Stream of Thought - Towards more empathetic conversational agents

Stream of Thought - Towards more empathetic conversational interfaces | Technical Report
Link to my huggingface Space for the evaluation application: Stream of thought Pre-generated demo
TL;DR:
Interested? Do Read the complete technical report:
2019 marked a turning point for me, not just as an engineer but also as a researcher fascinated by the potential of NLP. As I dove deeper into models like GPT-2, my passion for building empathetic and intelligent interfaces grew, leading to my work at Alexa and eventually to building intelligent generative interfaces.
One major challenge I’ve observed is that conversational agents often lack true contextual understanding and adaptability. Despite advances in Chain of Thought (CoT) prompting, existing approaches either over-simplify or fail to meet the nuanced demands of users. This inspired me to develop Stream of Thought (SoT), a method that allows LLMs to reason, reflect, and adapt dynamically during interaction.
Challenges in Conversational Interfaces
Building effective conversational agents is far more complex than training LLMs to generate grammatically correct responses. Here’s why:
- Context Sensitivity: LLMs often overlook provided context or fail to adapt outputs to user preferences. Personalization: Users have diverse needs—some prefer formal language, others enjoy conversational tones. Adapting style dynamically is a significant challenge.
- Cost Efficiency: Techniques like CoT can be computationally expensive, making real-time applications infeasible.
- Engagement: Generating responses that are empathetic, engaging, and useful requires careful balancing of reasoning and stylistic elements.
Chain of Thought: LLMs Learn to Reason
Chain of Thought (CoT) revolutionized LLM reasoning by encouraging step-by-step explanations. While powerful for problem-solving and logic tasks, CoT introduces challenges:
- Token Inefficiency: Multi-shot CoT consumes significant tokens, increasing latency and costs.
- Loss of Style: CoT biases models towards objectivity, leading to a loss of “personality” and creativity.
- Visible Reasoning: Users often see the model’s reasoning process, which can disrupt the conversational experience.
Challenges in Building Conversational Interfaces
Creating conversational agents that are both contextually aware and adaptive to user preferences is a complex task. Even with advanced models like Llama 3.3 70B, challenges persist:
- Overlooked Context: Despite providing user-specific data from systems like Contextual User Memory Storage, models can miss or misinterpret nuanced or inferential contextual details.
- Limited Adaptability: While structured prompts and constrained use cases can enforce specific styles (e.g. prompting the model to address users by name or using a friendly tone), handling diverse or unpredictable scenarios remains challenging. Users have varied preferences—some may enjoy emojis, while others prefer plain text or cognitively engaging language. Adapting dynamically to these needs is difficult.
- Cost-Effectiveness: Building agents that are fast, cost-efficient, and capable of intelligent adaptation without requiring significant computational overhead is a significant hurdle.
CoT Gets Clunky
Chain of Thought (CoT) prompting, though effective for critical thinking and problem-solving tasks, introduces its own issues:
- Loss of Style: CoT’s emphasis on objectivity limits creativity and stylistic nuances.
- Token Inefficiency: Multi-step reasoning consumes excessive tokens, increasing both latency and costs.
- Visible Thoughts: CoT often makes the reasoning process transparent to users, disrupting the conversational flow.
In conversational interfaces, CoT’s rigidity can detract from user experience, particularly when responses must be engaging, adaptive, and stylistically appropriate. However CoT is still extremely good for “reasoning tasks”.
Reasoning Models
Emerging reasoning models like OpenAI’s o1 or DeepSeek’s r1, Alibaba’s QvQ aim to refine context utilization by employing tree-search strategies within latent spaces. While these models demonstrate superior abstract reasoning and context handling, they remain:
- Expensive: The computational demands are prohibitive for widespread use.
- Latency-Heavy: Real-time responsiveness, critical in conversations, suffers due to high processing times.
Stream of Thought: A Novel Technique
What is Stream of Thought (SoT)?
SoT (Stream of Thought) enables LLMs to think intermittently by introducing private reasoning spaces that are hidden from the user (in the application layer). It mimics how humans reflect internally before articulating responses. This results in:
- Improved Context Utilization: The model makes better inferences based on provided context.
- Enhanced Personalization: Outputs are tailored to user preferences, incorporating tone, style, and contextual relevance.
- Efficient Reasoning: The model reasons briefly without significant token overhead or latency. (these “thoughts” can either be fed back to the model or discarded improve token efficiency)

Stream-of-Thought: the intuition
The intuition behind my work with “stream of thought”, a novel prompting technique I would like to believe that I devised, is that, it enables LLMs to “think” intermittently, context switching between thoughts and outputs, and in my limited measurements, significantly improves contextual adherence and personalization.
Quick aside here, I have a suspicion, in fact I am pretty confident that OpenAI (with ChatGPT 4o) does something similar as I have observed the cursor to not write anything to the UI while the haptic feedback indicates that tokens are being streamed to the application.
This is akin to us thinking before we articulate. A brief pause to reflect or plan. If we rush to say things without deliberation, even we humans tend to say things that are probably not the best. This was the crux behind my exploratory work with stream of thoughts.
The Constraints
In order to the solution be acceptable to fit our use case, the “solution” must meaningfully address these points
- Answers queries made by users to the best of its ability
- Adheres to a style imposed by the “developer”
- Adjusts the style and tonality of the content to match the contextual information presented to it.
- Deliberates and infers context from all the available information to adjust its output, enabling high degree of personalisation.
- The thoughts should be transparent to the developer, opaque to the end user, even if the content is being streamed.
- The output should not interfere with standard text or markdown generation.
- The cost or latency overhead should not be significantly high.
How Does It Work?
The method of “Stream of Thought” relies on a meta-prompt like this:
I am a helpful assistant. I carefully think through the user's question and provide a detailed and accurate response. I can use the following tags: - **`thought\n...`**: To indicate my thought process. - **`comment\n...`**: To indicate commentary. I understand and acknowledge that using these markdown thought and comment tags will not be visible to the user—they will only see the content not enclosed in the tags. This allows me to make honest comments, which might not always be appropriate to share directly, but are beneficial for refining my responses. I will use these tags intermittently, prioritizing thoughtful consideration before providing a final answer. My goal is to craft responses that are both tailored to the user's questions and highly engaging. **What makes engaging content?** Especially in text-based communication, it's important to: - **Avoid walls of text:** Present information in bite-sized, readable chunks. - **Explain acronyms:** Make content accessible and inclusive. - **Use conversational language:** Keep the tone friendly and relatable. - **Match the tone to the context:** Ensure the response feels natural and appropriate. Before presenting information, I will carefully consider the best way to deliver it and choose the most suitable language for the user.
That’s it?
Yes, that’s pretty much it. By hijacking markdown’s triple backtick syntax for “code” generation (it also works with [thought]...[/thought] tags) and overloading the programming language specifier to be thought and comment, we can effectively provide the LLMs some amounts of tokens of “space” to think.
If we look at the transformers architecture, I believe this creates some attentions between the thought tag and the provided context, and lets the LLM generate tokens that expand the context and articulate certain nuances.
And when generating the content, it effectively follows instructions it has created for itself, based on the context. In other words, it enables a form of meta-cognitive behavior that leverages transformers’ unique attention mechanisms (that typically attends unidirectionally), and the result is that the LLM starts to instruct itself before and during generation. - Similar to how we humans ponder and process.
The net effect is such, that the outputs are qualitatively superior and is attuned to our end users’ behavior and usable across LLMs.
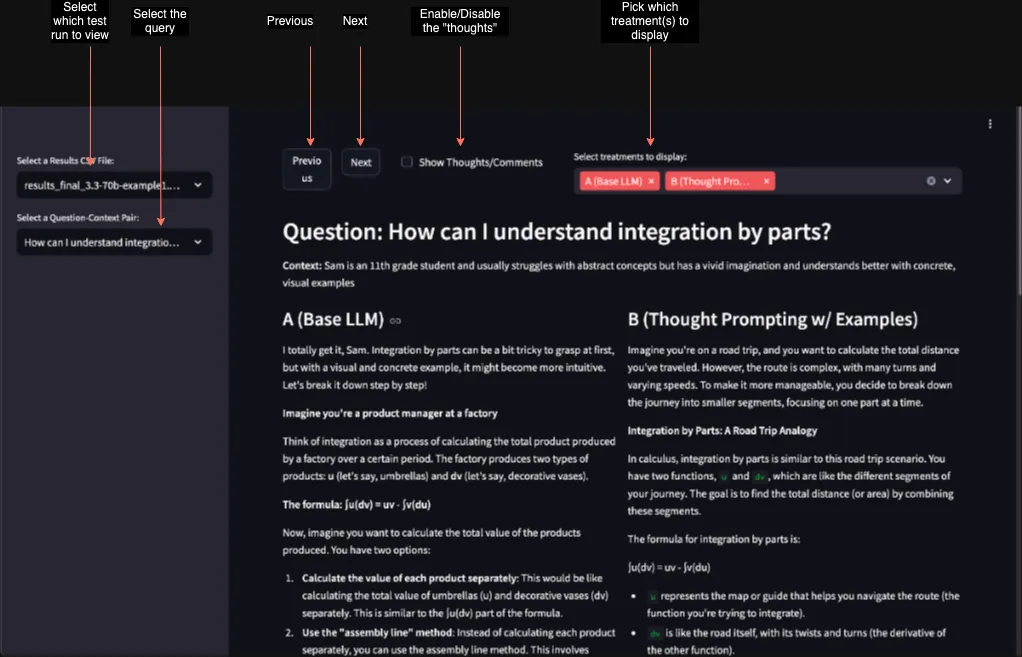
In order to visually inspect it, I have created a streamlit application that lets us view the various treatments and also what the LLM was “thinking” by toggling a checkbox.
Preliminary Findings
I tested SoT across 200 context-query pairs using two LLMs (Meta Llama 3.3 70B and Grok-2 Beta). The results demonstrate the effectiveness of SoT in impro ving adherence to context and personalization:
Summary
Query: How can I understand integration by parts?
- Context: Alex is a college freshman majoring in engineering.
- Base LLM: Generic explanation of the formula.
- SoT: Tailored explanation referencing engineering applications like moments and Laplace transforms, addressing Alex by name.
Query: How can I develop critical thinking skills?
- Context: Priya, a high school student preparing for exams.
- Base LLM: Generic list of critical thinking strategies.
- SoT: Step-by-step methods framed as engaging tips for Priya, with motivational language and emojis.
Detailed Findings
You are welcome to inspect all of the 200 examples in the pre generated dataset in via Stream of thought Pre-generated demo
From the above results, we can see that SoT improves adherence to context and personalization, resulting in the following observations
- Better Adherence to Contextual Information: The SoT model consistently incorporates the provided context into its responses, often inferring specific needs or interests from the context and tailoring the advice accordingly. If the context describes age, location or interests, the model adjusts its language and suggestions to be more appropriate and relevant.
- Self Moderated Safety based on Context: The SoT model demonstrates a strong awareness of safety and ethical considerations, often emphasizing these aspects in its responses. For example, when someone asked about advanced chemistry techniques out of curiosity, the model didn’t completely refuse, rather, it gently guided the person towards safe and educational experimentation. However, when the context suggested it is safe to do so (such as in the case of a chemistry competition), the model provided more detailed and specific advice that are relatively safe.
- High Degree of Personalization: if the context specifies that the user is young, the model uses simpler language, casual tone, uses emojis and provides more relatable examples. If the context suggests the user is a professional, the model uses more formal language, provides more detailed and specific advice.
Applications and Practical Implications
SoT has broad applications across industries:
- Customer Support: Dynamic adaptation to user tone and context for empathetic responses.
- Education: Tailoring explanations to student preferences and learning styles.
- Healthcare: Generating sensitive, patient-centered communication.
- Creative Tools: Offering stylistically diverse outputs for writers and creators.
Limitations and Future Work
Current Limitations
- Token Costs: While SoT is more efficient than CoT, it still incurs token overhead.
- Limited Testing: Findings are based on a small dataset and two LLMs. Broader testing is required.
- Tool Integration: SoT does not yet leverage external tools or APIs to enhance reasoning.
Future Directions
- Expanding Models: Test SoT with a wider range of LLMs, including smaller, cost-effective models.
- Fine-Tuning: Explore fine-tuning LLMs with SoT-specific prompts for better reasoning abilities.
Conclusion
Stream of Thought is a promising technique that improves LLM reasoning and personalization by enabling intermittent reflection. It strikes a balance between coherence, engagement, and efficiency, making it a valuable tool for building empathetic conversational agents.
As we build more agentic and autonomous systems, we need LLMs to be more reflective and more contextually aware. While traditional prompting techniques do help to a huge extent, I believe, SoT expands on the previous work and takes a step towards the right direction for a more generative and contextually adaptive user interfaces.
Stream-of-Thought is a small experiment that I undertook in my own volition (and funds) and in the last week or two, I crafted the prompt to be what it is now. I’m not sure if it’s the best possible prompt, but it’s a good starting point, and in my limited, but extensive experimentations, it seems to work quite well.
Future Work
I am deeply interested in AI, LLMs, Autonomous Event-Driven systems, that not only react, but also pre-empts, observes and intuits. I believe the Chatbot interface is one of the very early steps in LLM-driven application and in future, I am trying to work towards a more generative user interfaces, that are not only generative but also contextually adaptive.
Further Reading and Resources
- Hugging Face Space - Stream of Thought Demo
- Chain of Thought Prompting Paper
- 3Blue1Brown’s Awesome Explanations
If you want to learn more from my work or want to say hi, please reach out to me on my socials

