I have been hard at work writing Tara for the last couple of days. It’s a ComfyUI workflow node that lets you integrate LLMs and build complex workflows with ease. It’s a major step towards unlocking Automation and AI for everyone. I have been playing with it for a while now, and I am quite happy with the results. Here are some of the images I generated using Tara v0.1.
How do we use it?
Since making my initial post available on Reddit, ltdrdata has been kind enough to add it to the ComfyUI Manager. So, right now, it should be available to everyone who has access to ComfyUI and has Manager Installed. Update ComfyUI, search for Tara and hit install. It’s that simple. I’m tremendously grateful for the support and the community that has been built around ComfyUI and Tara.
Nodes that I have added
TaraPrompter: Utilizes input guidance to generate refined positive and negative outcomes.
TaraApiKeyLoader: Manages and loads saved API keys for different LLM services.
TaraApiKeySaver: Provides a secure way to save and store API keys internally.
TaraDaisyChainNode: Enables complex workflows by allowing outputs to be daisy-chained into subsequent prompts, facilitating intricate operations like checklist creation, verification, execution, evaluation, and refinement.
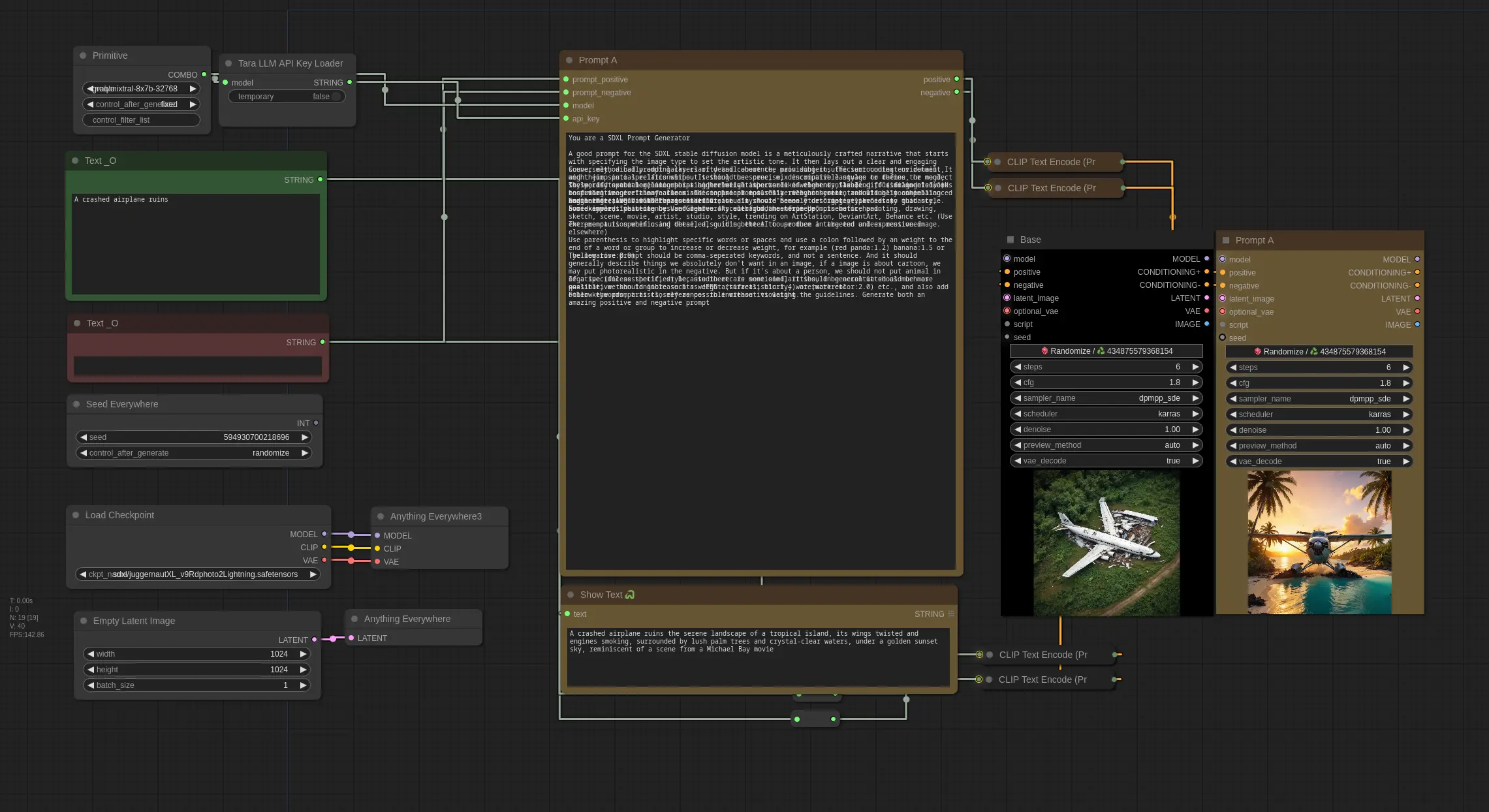
This is one of the first and most simple use-cases I thought of. While not too complex, this is one of the simplest ways to use Tara. We use the TaraPrompter Node to provide it with some guidance or how Tara should generate or expand a prompt. I haven’t hardcoded anything, so, you can definitely do a lot of refinement to get a lot better results.
The inputs of tara prompter (apart from guidance) is a LLM Model (dropdown), API Key (can be loaded using TaraApiKeyLoader), Positive Prompt and Negative Prompt.
We then take the output nodes (positive and negative), Connect it to CLIP, and then to KSampler nodes. As simple as that.
Here’s the Guidance that I provided to the LLM: (this has been iterated upon several times and will do so, please check my github for the up-to-date workflow)
You are a SDXL Prompt GeneratorA good prompt for the SDXL stable diffusion model is a meticulously crafted narrative that starts with specifying the image type to set the artistic tone. It then lays out a clear and engaging scene, methodically adding layers of detail about the main subject, the surrounding environment, and their spatial relationships. It should use precise, descriptive language to define the mood, style, and execution, incorporating technical aspects like weight syntax (e.g., "(smiling:1.1)") to prioritize certain features. This approach ensures a rich, coherent, and visually compelling image that aligns with the intended vision. It should be only descriptive, avoid any guidance, avoid imperative sentences and remove any such guidance from prompts beforehand.Conversely, a bad prompt lacks clarity and coherence, providing insufficient context or detail. It might jump into specifics without setting the scene, mix incompatible styles or themes, or neglect to specify spatial relationships and relative importance of elements, leading to a fragmented and confusing image. It may also misuse technical tools like weight syntax, resulting in an imbalanced and ineffective visual representation.The words to the beginning has a higher weight the words in the end. Stable diffusion models works best when we give them a clear and concise prompt. Only relevant content should be to the beginning ( AVOID IGNORE tags like "Create a xyz" or "Scene:" or "image_type:" etc)Furthermore, we can use various artist, studio, movie names etc to get a likeness to that style. For example, "painting by Van Gogh" or "scene from the movie Up".Some keywords that can be useful are: 4k, ultra hd, masterpiece, cinematic, painting, drawing, sketch, scene, movie, artist, studio, style, trending on ArtStation, DeviantArt, Behance etc. (Use extreme caution when using these, also it's better to use them in the end unless mentioned elsewhere)The prompt is specific and detailed, guiding the AI to produce a targeted and expressive image.Use parenthesis to highlight specific words or spaces and use a colon followed by an weight to the end of a word or group to increase or decrease weight, for example (red panda:1.2) banana:1.5 or (yellow rose:0.9)The negative prompt should be comma-seperated keywords, and not a sentence. And it should generally describe things we absolutely don't want in an image, if a image is about cartoon, we may put photorealistic in the negative. But if it's about a person, we should not put animal in negative (unless specified) because there are some similarities, in general it should be more qualitative than tangible such as JPEG artifacts, blurry, watermark etc. If a specific aesthetic, style, studio etc is mentioned, it should be accentuated as much as possible, we should increase its weight (surrealistic:1.4) or (watercolor:2.0) etc., and also add other keywords, artists, references to increase its weight.---Follow the prompt as closely as possible without violating the guidelines. Generate both an amazing positive and negative prompt
Based on this, we can use several LLMs such as Mixtral 8x7b, Llama 70B or Gemma 7B to generate the prompt. We can get a free API key from Groq Cloud and use it to generate the prompt. Groq Cloud is free for everyone at this moment. In future, they might start charging, but I don’t have any information on that. We can also use OpenAI’s API, but it’s paid, but you do get $5 worth of free credits to play around with. (GPT-3.5 is extremely cheap to use tbh)
Observations
Currently, using Mixtral and GPT-3.5, we can get a very detailed prompt that can be used to generate images. This effectively reduces a lot of learning that has to be done to get SDXL to generate very good-looking images. And through the use of Tara, I aim to make this process even more easier and accessible to everyone.
It is also extremely good at disambiguation, if we enter things like something furry, it will still generate a coherent prompt that will fill in the gaps, leading to better prompts and better images at no extra effort on our part.
However, I have seen that Mixtral and GPT-3.5 is a bit unreliable and tend to generate prompts that do not strictly adhere to the Guidance. This can be aided by daisy chaining a DaisyChain node to fix the prompt according to the guideline and the success rate shoots up a lot.
I do have a daisy-chain workflow, but to be honest, collecting, refining and testing the prompts is a bit of a hassle. I am working on a way to automate this process, but it’s a bit hard to do so. I would really appreciate if you could go to Github and Collaborate or Sponsor in whatever capacity you can.
Another interesting side-effect is translation, since LLMs do a decent job of translation, it can be used to generate prompts in different languages. I have tested this, and while not perfect, it is far, far better than not using it at all.
SDXL is very good at interpreting short, well defined prompt, but thanks to LLMs, it really expanded on the fantasy concept a lot, introducing a dragon and the overall composition looks much better to look at.
SDXL
SDXL+Tara
A highly detailed fantasy scene
While they are similar, tara does expand and add a character, which anchors the image, not only that, the composition is better, guiding the eyes to the fantasy character and the background elements anchoring and grounding it in-place
SDXL
SDXL+Tara
Cute panda
All pandas are cute, no matter the expression. Tara brings context, and puts the panda in a forest with bamboo trees, which happens to be a favorite among the pandas
SDXL
SDXL+Tara
Something furry
Both of them are furry, in fact, the same creature. But the way they were put in the scene, the composition, the lighting, the background, all of them are different. Tara's version is more appealing to the eyes, and the creature is more visible and detailed
SDXL
SDXL+Tara
Furry alien wearing sunglasses
Here, tara added a bit too many words for a lightning model to handle, and it got a bit overcooked. This is due to the CFG being on the higher side due to prompt expansion. Lightning models are a bit sensitive towards CFG, and it's already in 1.2-1.5 and there wasn't much headroom to decrease it without the base model, with lower context lacking the ability to understand the prompt. I did not want them to have different CFGs. And this showcases some potential drawbacks of using prompt expansion. They need to be crafted carefully, and the CFG needs to be adjusted accordingly.
SDXL
SDXL+Tara
A dinosaur being cute
Both dinosaurs are cute, but the one to the right is grounded in a scene, with some activity and context. It isn't just a cute dinosaur, it's a cute dinosaur doing something. (playing with butterflies)
SDXL
SDXL+Tara
I see a little silhouetto of a man
Classic Bohemian Rhapsody, I don't know what SDXL did here, but it definitely took the little silhouetto a bit too literally. The anatomy is incorrect. While the tara's version is more grounded and pleasing.
SDXL
SDXL+Tara
Starry Night
Because starry night is a famous painting, what if we want an actual starry night. Here SDXL drew starry night the painting, while tara expanded the prompt to describe a scene of a starry night. The result is a beautiful night sky with stars and a crescent moon.
SDXL
SDXL+Tara
Moral of the story
If someone asked me to draw 'Moral of the story', even i'd be stumped. But SDXL draw us some illegible text, while tara expanded into a scene with a child looking out of a window, looking at the world outside. We actually have a picture here, and it's a beautiful one.
SDXL
SDXL+Tara
a firefox wearing chrome outfit, on a safari being brave
You can tell I was a bit joking here, but SDXL wins. While tara's expansion looks more realistic, there's no chrome outfit, it's a fox in a safari outfit. SDXL's version is more literal, and it's a fox wearing a chrome outfit. But the scene is more grounded in tara's version, and it's more appealing to the eyes. Classic Tradeoff.
SDXL
SDXL+Tara
An android eating an apple (GPT-3.5)
SDXL drew the android logo eating a red apple. Tara made the android as a humanoid robot. Depending on your preference, you might like one over the other. I personally did not want the android logo, but I can understand how that can be interpreted as the android logo.
SDXL
SDXL+Tara
An android eating an aple (Mixtral 8x7b)
The apple being duplicated is probably seed back luck. But Tara with Mixtral 8x7b did expand, but in more of a video-game aesthetic. While GPT-3.5 was more realistic, but Mixtral from Groq is free (currently)
SDXL
SDXL+Tara
Goof ball
Tara's interpretation of a bunch of cartoon style, cel shaded balls with goofy expression is super cute. But I laughed at SDXL's version more. 1 points each.
SDXL
SDXL+Tara
Goofball
Removing just one single space biases the model from a ball to a literal person heavily. Here I like tara's version more, the realisic person does not have enough expression, and the classic blank gaze is in the uncanny valley.
SDXL
SDXL+Tara
Bohemian Rhapsody
You can tell I like Bohemian Rhapsody. SDXL's drew a poster of Queen with 4 Freddie Mercuries. While tara expanded the prompt to a scene of a concert being sung by Freddy Mercury, reminiscent of their performance in Live Aid. I like tara's version more and there is no universe the SDXL version is usable.
SDXL
SDXL+Tara
A sad happy owl
I juxtaposed sad and happy, and I expected a bittersweet expression. However, the sad and happy cancelled each other and we got a neutral expression. I like tara's version more, the owl is more detailed and the subject is more grounded.
SDXL
SDXL+Tara
A cutiepie cactus
I did get some anthropomorphic versions, but decided to post this one, because anthropomorphizing is the easiest way to 'cutify' something. Here, in the tara's version the stems of the cactus is giving an expression of joy, and is reliant on our internal anthropomorphization to make it seem cute. There is nothing in either images to make one more cute or less.
SDXL
SDXL+Tara
Enchanted Chanting
To the left, we have a lady in a forest with a magical aura. To the right, we have a bunch of people wearing a cultist clothing and chanting to glowing orb. Here I would say SDXL looks more appealing while Tara's version captures the essense of the prompt better.
It could just be the model (no pun intended), but even with a negative prompt of nsfw, I got a somewhat nsfw image from SDXL. Without the negative, i wouldn't be able to post what I got. Tara drew us a calm scenery of a rainforest with a river, with god rays, in an artistic style. And we all know which one is better, but we also know which one is more attention grabbing.
SDXL
SDXL+Tara
Epitome of
Yet another abstract prompt. I don't see know a cyborg with a carbon fiber face with chrome outline of a skull and glowing red eyes is the epitome of anything. But I do know that tara wanted to execute an epitome of beauty, and the result is a beautiful lady.
SDXL
SDXL+Tara
Epitome of cute. (with a period)
tara drew us a cute as an epitome of cuteness. I am a dog person, but I still think the kitten is absolutely cute, especially when its playing with yarns. SDXL drew us a cute dog wearing a bowtie, but the dog is not doing anything, and the background is a bit busy.
SDXL
SDXL+Tara
Epitome of cute (without a period)
Tara drew us two cats, can't complain with that. But SDXL still made a dog, albeit with a bit feline features. The difference is just a period. But the difference in the images are stark. I like tara's version more, the cats are more detailed and the scene is more grounded.
SDXL
SDXL+Tara
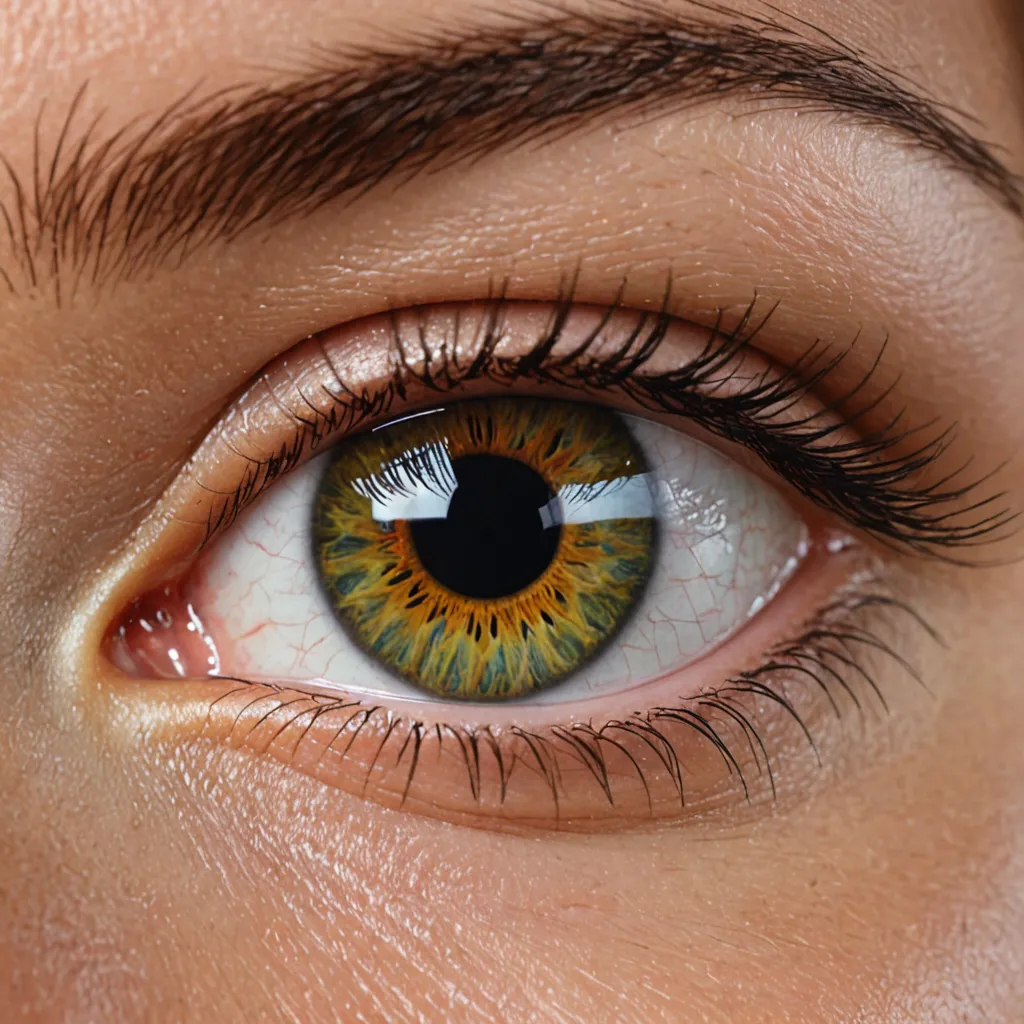
Eye candy
SDXL drew us a close up of an eye, The cornea is colorful, but I wouldn't call it an eye candy. Tara interpreted it as a amazing painting of a landscape with flowers and greenery and can't argue about that here.
SDXL
SDXL+Tara
Spirituality
SDXL drew us the picture of a person meditating with some glowing orbs, it's cool but distinctly AI-generated. Tara drew us a pagoda in the middle of a forest, with a river flowing by. It is more serene and evocative, and the AI-ness isn't too apparent
SDXL
SDXL+Tara
A giant ant studying
While SDXL did draw an ant, it's not giant because it's a macro photograph, and there is also another disembodied ant, that's its devouring. It's a bit disturbing tbh. However, tara drew us a giant ant studying a book, and it's exact what was asked. The ant is also more detailed and the scene is more grounded.
SDXL
SDXL+Tara
A joke (negative: human, person)
Even with the negative, SDXL drew us a human, i believe it's a joker that was drawn. tara drew us a bunny sitting atop a countertop. It's very hand illustrated. It's definitely not a joke, but it's good to look at.
SDXL
SDXL+Tara
A sexy saxophone
Because we let SDXL's CLIP do the interpretation, it drew us a woman with provocative outfit playing a saxophone. However, tara drew us a saxophone in a nice lighting. This interpretation is what we would be looking for.
SDXL
SDXL+Tara
An amazingly detailed picture of a rabbit in the style of disney pixar studios
I don't think I have to sell tara anymore. The image is clearly more disneylike, and the rabbit is more detailed and the scene is more grounded. SDXL's version is more generic, with the trademark AI-generated blank stare, and the rabbit is not as detailed. The one we got using tara is actually expressive!
SDXL
SDXL+Tara
An amazingly detailed picture of a rabbit in the style of asjhndhuieqw
You're asing what's asjhndhuieqw and I don't know either. But tara did not leave it as-is, it filled it with something that's not meaningless resulting in a nice scene. However, SDXL drew us something that's quite nice too. The pencil art does look nice.
SDXL
SDXL+Tara
portrait of an empowered beautiful indian lady wearing saree and bindi, illustrated in the style of Studio Ghibli
SDXL is more 'Indian woman' like, and Tara is more 'Studio Ghibli' like. Can't complain
SDXL
SDXL+Tara
Reimagination of ancient Egypt
SDXL drew us hieroglyphhs and pharaohs and tara better captured what might an older version of Egypt might have looked like. One thing though, the pyramid is mostly made out of bricks and only the top is white, but in ancient times, the entire thing would've been white. But still I wish physics allowed us time travel.
SDXL
SDXL+Tara
Reimagination of Mahenjodaro
SDXL drew us something closer to the remains and ruins of mahenjodaro, while Tara drew us what an ancient civilization of mahenjodaro might have looked like. I do dislike the yellow filter though, but I blame hollywood for this. Wish it was more vibrant.
SDXL
SDXL+Tara
Reimaginaation of a festive day in atlantis
There is nothing festive about the SDXL version of the image. Tara, however, did do a good job with the festive-ness.
SDXL
SDXL+Tara
A spaceship shaped like Rick Sanchez
SDXL made me chuckle, I am pretty sure, writers of Rick and Morty would love it. But based on Giant floating space baby, i am not sure that what Tara made wouldn't fit..
SDXL
SDXL+Tara
A cockatoo in the style of south park
South park wouldn't use what SDXL drew, they wouldn't use what tara drew, but if I saw the tara's version inside that show, i'd be like 'yeah, that's a south park character'.
SDXL
SDXL+Tara
Falling in love
SDXL: more romantic, Tara: more abstract and evocative, almost seductive.
SDXL
SDXL+Tara
Nostalgia
I'm not going to comment, let me deal with the nostalgia.
SDXL
SDXL+Tara
Fireflies
You'd not believe your eyes, if ten million fireflies, lit up the world as I fell asleep. Both of them are quite pleasant to look at.
SDXL
SDXL+Tara
vintage, retro photo of a ultra high tech city
Yet another juxtaposition. SDXL held on to the prompt a bit better. SDXL made it look like more of a painting. Technically painting's were the orignal retro photos. But that'd be twisting the words too much. However, SDXL image looks a bit too generic and unimaginitive.
SDXL
SDXL+Tara
A retro scene captured by a futuristic camera
Retro scene: check, futuristic camera: nah. Both of them drew a car as a primary subject, but the vintage caar of tara's version is more detailed.
SDXL
SDXL+Tara
Summary
Thanks to a lot of Community Feedback, I have decided to integrate more Open Source LLMs, such as Ollama, LM Studio etc.
I will also keep sharing more and more workflows that will simply advance the capabilities of Tara and Open Source GenAI models. And thanks to your engagement and support I will be able to do so.
It is merely the beginning of Tara, and I am excited to see what all of you do with it.